八、样本变异
小于 1 分钟
import pandas as pd
import numpy as np
from scipy.stats import norm
%matplotlib inline
# Sample mean and SD keep changing, but always within a certain range
Fstsample = pd.DataFrame(np.random.normal(10, 5, size=30))
print('sample mean is ', Fstsample[0].mean())
print('sample SD is ', Fstsample[0].std(ddof=1))sample mean is 10.14251947495814
sample SD is 4.114798060251902
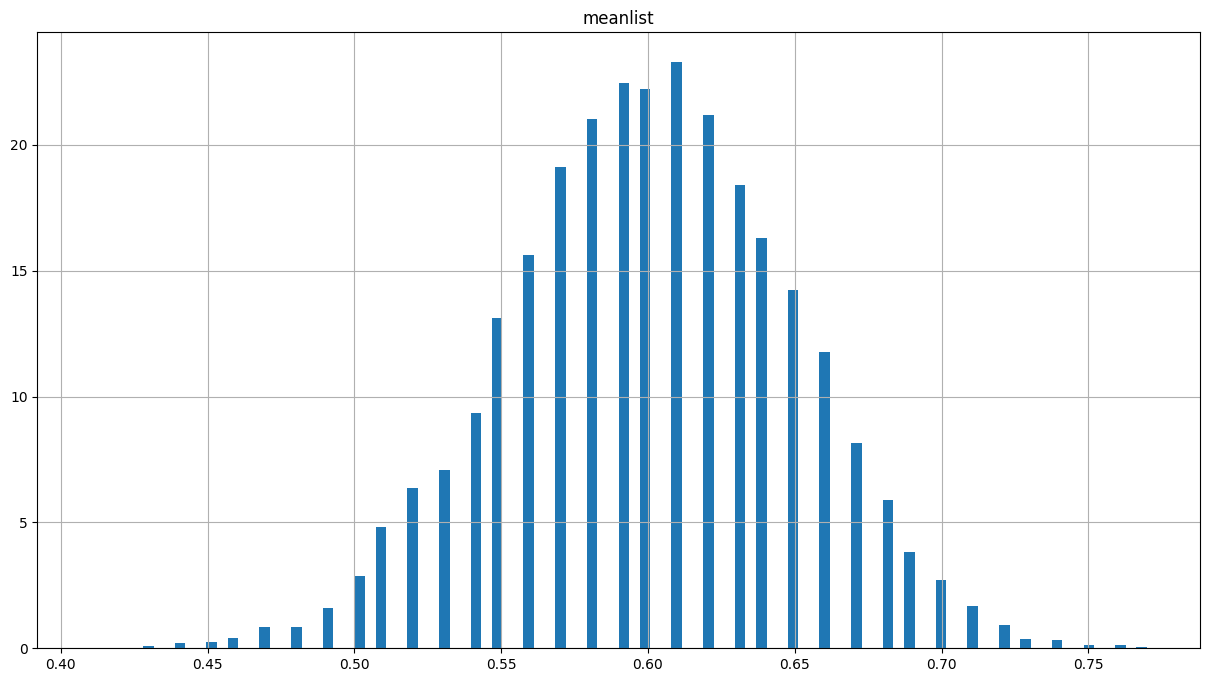
Empirical Distribution of mean
meanlist = []
for t in range(10000):
sample = pd.DataFrame(np.random.normal(10, 5, size=30))
meanlist.append(sample[0].mean())
collection = pd.DataFrame()
collection['meanlist'] = meanlist
collection['meanlist'].hist(bins=100, density=True,figsize=(15,8))<matplotlib.axes._subplots.AxesSubplot at 0x7f1898f9ee10>
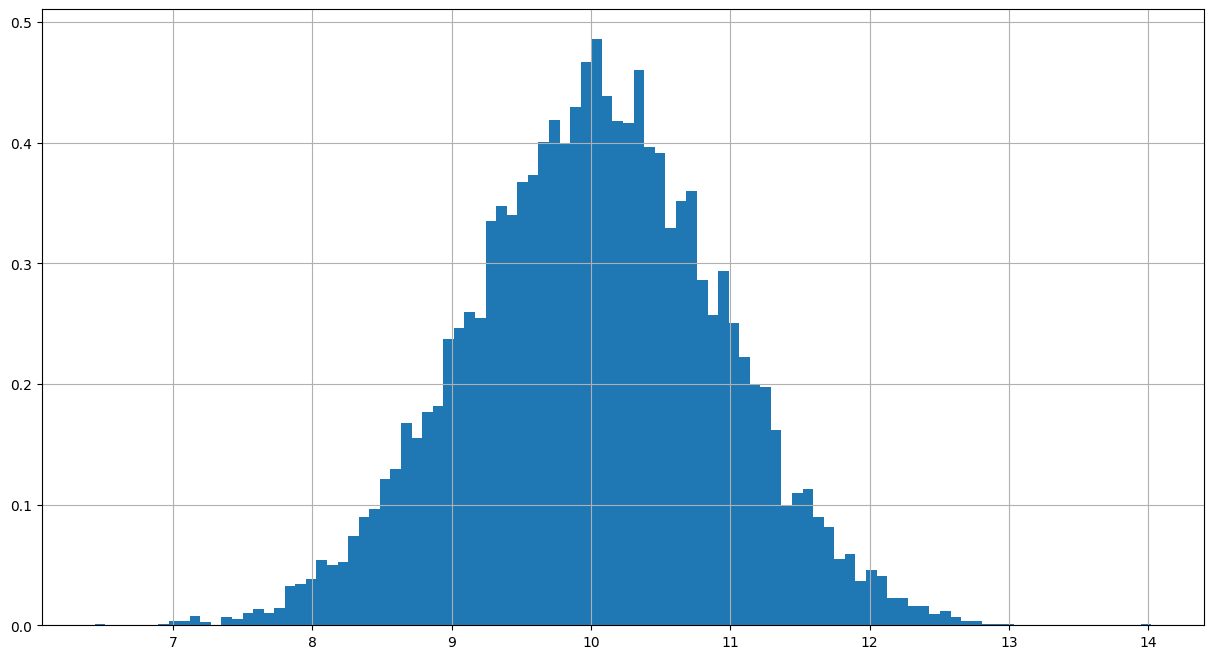
Sampling from arbritary distribution
# See what central limit theorem tells you...the sample size is larger enough,
# the distribution of sample mean is approximately normal
# apop is not normal, but try to change the sample size from 100 to a larger number. The distribution of sample mean of apop
# becomes normal.
sample_size = 100
samplemeanlist = []
apop = pd.DataFrame([1, 0, 1, 0, 1])
for t in range(10000):
sample = apop[0].sample(sample_size, replace=True) # small sample size
samplemeanlist.append(sample.mean())
acollec = pd.DataFrame()
acollec['meanlist'] = samplemeanlist
acollec.hist(bins=100, density=True,figsize=(15,8))array([[<matplotlib.axes._subplots.AxesSubplot object at 0x7f188f4bc898>]], dtype=object)